Apktool: Fixing Bug 761
This is my second technical blog exploring the steps taken to add support for BCP47 to Apktool.
The February 16th daily of Cyanogenmod had an interesting error. The decode went alright, but spat out a common directory error on rebuild.
$ apktool d Settings.apk
I: Using Apktool 2.0.0-RC4 on Settings.apk
I: Loading resource table...
I: Decoding AndroidManifest.xml with resources...
I: Loading resource table from file: 1.apk
I: Regular manifest package...
I: Decoding file-resources...
I: Decoding values / XMLs...
I: Baksmaling classes.dex...
I: Copying assets and libs...
I: Copying unknown files...
I: Copying original files...
$ apktool b Settings
I: Using Apktool 2.0.0-RC4
I: Checking whether sources has changed...
I: Smaling smali folder into classes.dex...
I: Checking whether resources has changed...
I: Building resources...
invalid resource directory name: Settings\res\values-?@-rES
These "invalid resource directory name" errors are thrown by aapt. You can see in tools/aapt/AaptAssets.cpp in slurpResourceTree().
bool b = group.initFromDirName(entry->d_name, &resType);
if (!b) {
fprintf(stderr, "invalid resource directory name: %s %s\n", srcDir.string(),
entry->d_name);
err = -1;
continue;
}
So apktool produced a qualifier that aapt rejected. Obviously looking at the folder of values-?@-rES. There is something wrong there. (?@) is not a qualifier, so something went amiss. Thankfully with qualifier errors we can leverage aapt to identify the qualifiers that were suppose to be there.
aapt d configurations Settings.apk | grep ES
ast-ES
gl-ES
gl-ES-nokeys
eu-ES
eu-ES-nokeys
Now the problem is the first qualifier of ast-ES. The language and region qualifier are bound by the two letter ISO 639-1 (language) followed by a two letter ISO 3166-1-alpha-2 (region). Both language and region have a maximum of 2 characters, yet I'm looking at a 3 character language above.
My first step was to figured out what ast was. ES is Spain, but I had never seen a 3 letter language before. Since Cyanogenmod utilizes CrowdIn. I went to their page and checked out all languages beginning with an A.

There it was, plain as day. Asturian was added to Cyanogenmod, yet it had a 3 letter qualifier when every other language had 2. My Cyanogenmod device handled these apks fine, but apktool failed. Somehow I missed a qualifier change during the Lollipop update.
I usually visit the ResourceTypes page to find changes to qualifiers. As of this blog post (4/10/2015) there is no mention of what we will soon figure out to be the addition of the BCP47 qualifier and a clever 3 letter packed byte trick.
When the documentation fails, my secondary choice is examining the platform_frameworks_base commit history. The file that controls the qualifier(s) is platform_frameworks_base/include/androidfw/ResourceTypes.h. So I examined the history involving that file.
It didn't take long.
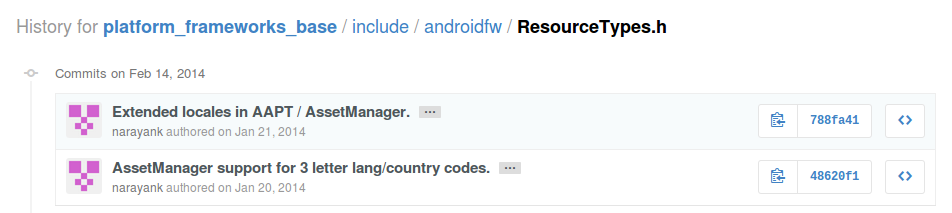
The commit message for the first commit, answered the question.
AssetManager support for 3 letter lang/country codes.
- 3 letter codes are packed into the existing 32 bit locale
field in ResTable_config - We introduce new fields for script / variant information.
but wait. Re-read that. "3 letter codes are packed into the existing 32 bit locale field". 32 bits = 4 bytes. 4 bytes = 4 characters. How in the right mind can you get (ast-ES) in 4 bytes. 5 characters cannot fit in 4 bytes. What kind of magic is going on here.
Thankfully, AOSP added some comments.
union {
struct {
// This field can take three different forms:
// - \0\0 means "any".
//
// - Two 7 bit ascii values interpreted as ISO-639-1 language
// codes ('fr', 'en' etc. etc.). The high bit for both bytes is
// zero.
//
// - A single 16 bit little endian packed value representing an
// ISO-639-2 3 letter language code. This will be of the form:
//
// {1, t, t, t, t, t, s, s, s, s, s, f, f, f, f, f}
//
// bit[0, 4] = first letter of the language code
// bit[5, 9] = second letter of the language code
// bit[10, 14] = third letter of the language code.
// bit[15] = 1 always
//
// For backwards compatibility, languages that have unambiguous
// two letter codes are represented in that format.
//
// The layout is always bigendian irrespective of the runtime
// architecture.
char language[2];
// This field can take three different forms:
// - \0\0 means "any".
//
// - Two 7 bit ascii values interpreted as 2 letter region
// codes ('US', 'GB' etc.). The high bit for both bytes is zero.
//
// - An UN M.49 3 digit region code. For simplicity, these are packed
// in the same manner as the language codes, though we should need
// only 10 bits to represent them, instead of the 15.
//
// The layout is always bigendian irrespective of the runtime
// architecture.
char country[2];
};
uint32_t locale;
};
This is what we wanted.
// - A single 16 bit little endian packed value representing an
// ISO-639-2 3 letter language code. This will be of the form:
//
// {1, t, t, t, t, t, s, s, s, s, s, f, f, f, f, f}
//
// bit[0, 4] = first letter of the language code
// bit[5, 9] = second letter of the language code
// bit[10, 14] = third letter of the language code.
// bit[15] = 1 always
//
As you can see. They managed to pack 3 letters into 2 bytes (16 bits). It appears the high bit (bit 15) is thrown when utilizing this 3 letter qualifier. That leaves 5 bits per letter for a total of 16 bits (1 + 3(5) = 16)
So lets work through this with ast trying to replicate the byte combination used. Using an ASCII table.
- a = 61
- s = 73
- t = 74
Already I spot a problem. If you aren't familiar with binary each digit in binary represents a power. The below picture should explain it better than I can.

The first digit is 2^0, then 2^1, etc.
However that is 8 bits. As mentioned above, we only have 5 bits to represent these characters.
This changes our image to this.
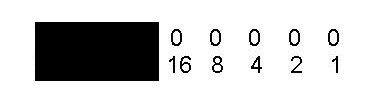
Except what is the max of a 5 bit binary string? Well 1+2+4+8+16 = 31 or binary 11111. Shown above we have 61, 73 and 74. We cannot represent those digits with 5 bits. We have a problem.
Examining the commit that introduced this change I find the packLanguageOrRegion method which appears to handle the character to byte conversion.
void packLanguageOrRegion(const char in[3], const char base, char out[2]) {
if (in[2] == 0) {
out[0] = in[0];
out[1] = in[1];
} else {
uint8_t first = (in[0] - base) & 0x00ef;
uint8_t second = (in[1] - base) & 0x00ef;
uint8_t third = (in[2] - base) & 0x00ef;
out[0] = (0x80 | (third << 2) | (second >> 3));
out[1] = ((second << 5) | first);
}
}
It seems AOSP subtracts some char base from the bytes before bit shifting them into position. So I figured out what calls this method.
packLanguageOrRegion(language, 'a', this->language);
packLanguageOrRegion(region, '0', this->country);
From this it appears any packed language has a subtracted from it while any region has 0 subtracted from it. Could it be this simple? The a ASCII value is 61. So lets subtract 61 from our previous values.
- a =
61 - 61 = 0 - s =
73 - 61 = 12 - t =
74 - 61 = 13
Thus
- a =
0 - s =
12 - t =
13
Each of these digits can be packed into 5 bits.
- a =
00000 - s =
01100 - t =
01101
So at least we know and understand how 3 letters are fitting into 2 bytes. This base value is substracted from the characters and then added on later so they can fit in 5 bits. Quite an interesting method.
So lets get started on working on a patch. It appears the decoding for language and region has been changed to this unpackLanguageOrRegion function instead of just reading the chars directly from the stream.
Below the c++ version.
size_t unpackLanguageOrRegion(const char in[2], const char base, char out[4]) {
if (in[0] & 0x80) {
// The high bit is "1", which means this is a packed three letter
// language code.
// The smallest 5 bits of the second char are the first alphabet.
const uint8_t first = in[1] & 0x1f;
// The last three bits of the second char and the first two bits
// of the first char are the second alphabet.
const uint8_t second = ((in[1] & 0xe0) >> 5) + ((in[0] & 0x03) << 3);
// Bits 3 to 7 (inclusive) of the first char are the third alphabet.
const uint8_t third = (in[0] & 0x7c) >> 2;
out[0] = first + base;
out[1] = second + base;
out[2] = third + base;
out[3] = 0;
return 3;
}
So a fairly easy port to java.
private char[] unpackLanguageOrRegion(byte in0, byte in1, char base) throws AndrolibException {
// check high bit, if so we have a packed 3 letter code
if (((in0 >> 7) & 1) == 1) {
int first = in1 & 0x1F;
int second = ((in1 & 0xE0) >> 5) + ((in0 & 0x03) << 3);
int third = (in0 & 0x7C) >> 2;
// since this function handles languages & regions, we add the value(s) to the base char
// which is usually 'a' or '0' depending on language or region.
return new char[] { (char) (first + base), (char) (second + base), (char) (third + base) };
}
return new char[] { (char) in0, (char) in1 };
}
At this point we correctly had char[]'s that represented 3 character languages. However, we didn't have the correct locales being printed. A bit of hackery checking the length of language and region allowed an adaption to getLocaleString(). This was able to handle the 3 letter packed language.
I then decoded the original apk and checked the /res folder.
$ apktool d Settings.apk
I: Using Apktool 2.0.0-dc02ab-SNAPSHOT on Settings.apk
I: Loading resource table...
I: Decoding AndroidManifest.xml with resources...
I: Loading resource table from file: 1.apk
I: Regular manifest package...
I: Decoding file-resources...
I: Decoding values */* XMLs...
I: Baksmaling classes.dex...
I: Copying assets and libs...
I: Copying unknown files...
I: Copying original files...
$ cd Settings/res
$ ls -l | grep ast
drwxrwxr-x 2 ibotpeaches ibotpeaches 4096 Feb 25 17:01 values-ast-rES
Yay! We correctly decoded a 3 letter language.
Though I knew my work was not yet finished, because I spied a qualifier change while looking at the previous commits.
Hiding without Android documentation in the ResourceTypes.h file was this addition.
// The ISO-15924 short name for the script corresponding to this
// configuration. (eg. Hant, Latn, etc.). Interpreted in conjunction with
// the locale field
char localeScript[4];
// A single BCP-47 variant subtag. Will vary in length between 5 and 8
// chars. Interpreted in conjunction with the locale field.
char localeVariant[8];
Wow. They added 12 bytes to the ResConfig header. Usually we see 2 byte additions every few versions, but AOSP added 12 bytes on Lollipop.
This was the first mention of BCP-47 I saw. This stands for Best Current Practice. Though researching BCP-47 in the scope of Android was very difficult.
Documentation was next to none and my only hits were from the AOSP commits, bug tracker and unit tests. It appears they wanted to "soft" launch this change as I cannot find any proof of its existence in any Android developer documentation. The unit tests proved to be exactly what I needed.
This showed qualifiers such as
values-b+engvalues-b+eng+Latnvalues-b+en+US+POSIXvalues-b+eng+419
It appears the pattern of -b+ signals a BCP tag. So basically if script or variant was not equal to null than I knew it was a BCP tag. Which was an easy addition to our ARSCDecoder.java and ConfigFlags.java.
char[] localeScript = {'\00'};
char[] localeVariant = {'\00'};
if (size >= 48) {
localeScript = this.readScriptOrVariantChar(4).toCharArray();
localeVariant = this.readScriptOrVariantChar(8).toCharArray();
}
size corresponds to the size of the header. Prior to this change it was 36. 36 + 12 = 48. This helps Apktool from breaking on older apks by only reading data if it is there.
Quite a complicated pattern of language, region, script and variant. Since after you had the variables populated, in what order did the locales can get written? Was it script before variant or vice versa? There were a couple edge cases to handle, which made this a boring fix. No documentation. Just trying to replicate the unit-tests in AOSP and making sure Apktool could handle those.
Once applications start utilizing this unknown BCP-47 feature, a bug or two might be discovered. Until there is some real world results, I'm not quite sure if I handled support for every combination of language, region, script and variants.
Though, the main concern is that the 3 letter language had been fixed and merged into master.
Timeline