The birth of an open source project

On July 1st, 2019 Google open sourced their robots.txt parser. Something that was written 20 years ago and updated with the evolving web. I really enjoy reading the code of open sourced projects, even if I don't understand it. Very rarely do companies also open source the commit history, but when they do - that is even more interesting.
However, what I've noticed is a common pattern in every single existing project that has been open sourced. The larger the company open sourcing and the larger the code base just increases this phenomenon.
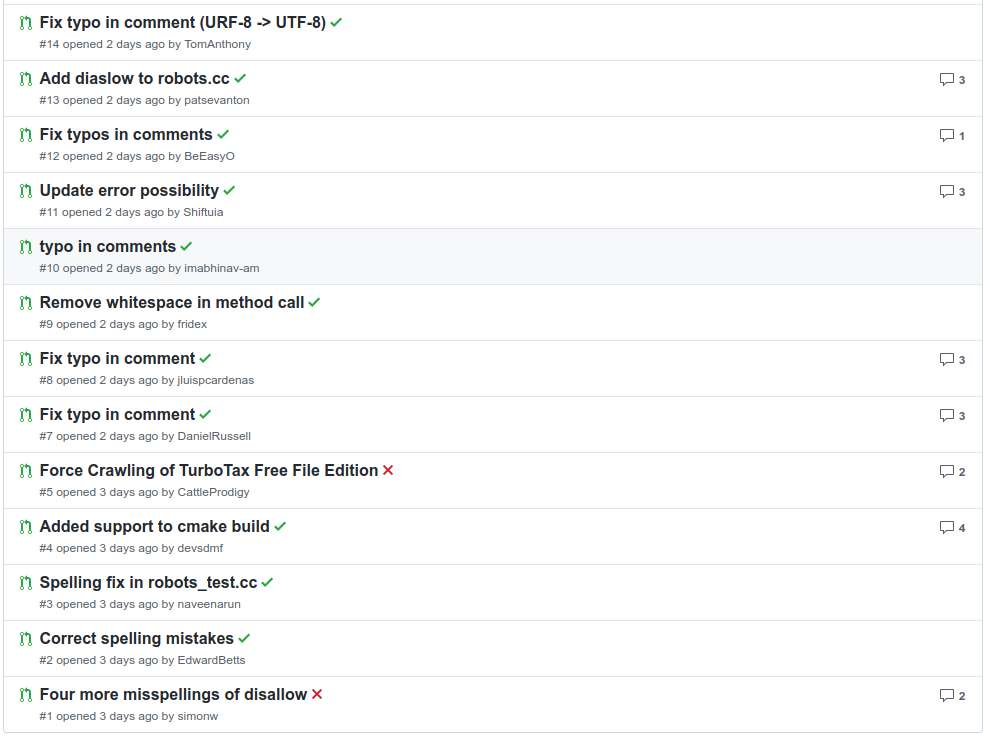
The above image shows what I'm talking about. Out of the first 14 pull requests to the project, we can group them into the following categories.
- 7 spelling fixes
- 3 real code contributions
- 2 unneeded code contributions
- 1 style fix
- 1 bad code contribution
I know the first question is "how do you determine a bad code contribution?". Well, lets dive into it.
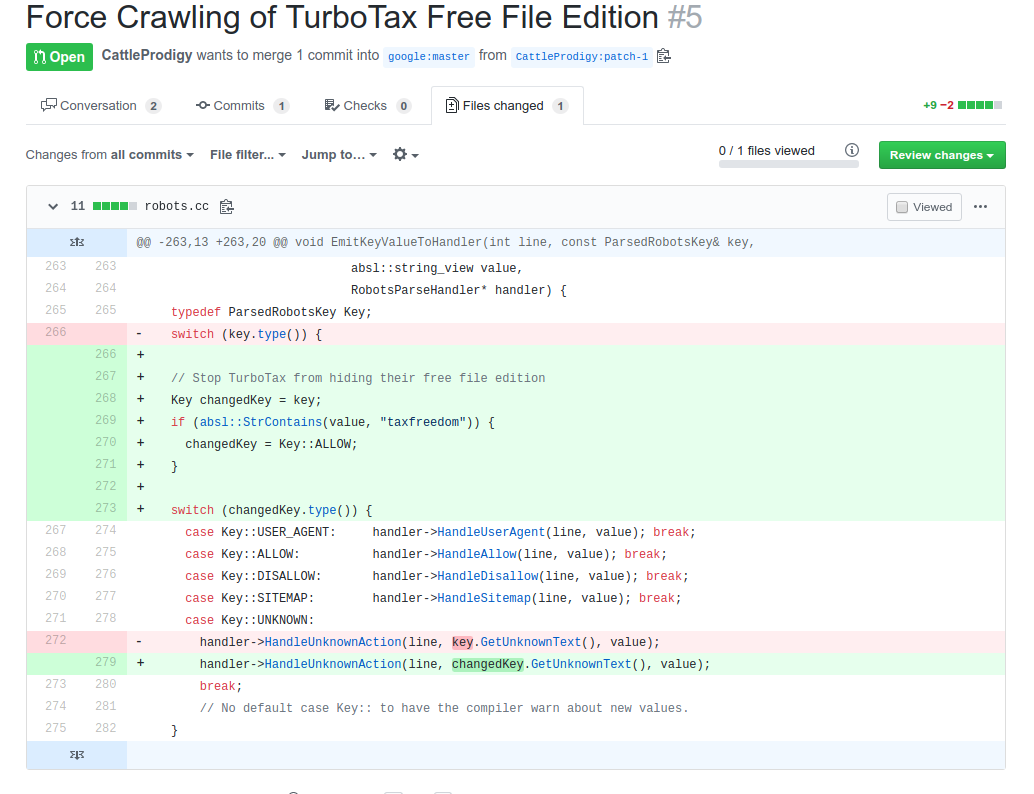
This change is requesting that the Google robots.txt parser that runs probably on a couple thousand computers should be patched to explicitly check for Turbo Tax Free edition and allow it to be indexed. There are so many reasons why this is wrong and won't be accepted, but it blows my mind that someone put forward this change request hours after the project went open source.
Was this person just itching to get Turbo Tax indexed online? Was is a big joke? I have no idea, but we are more interested in the obsession with getting spelling fixes into the code base.
- Correcting "against" and "initialized" - #2
- Correcting "anywhere" - #3
- Correcting "terminated" - #7
- Correcting "initialized" - #8
- Correcting "against" - #10
- Correcting "outside" - #12
- Correcting "utf-8" - #14
For me, it is slightly upsetting for a code-base to go public and the only thing people want to do is correct grammar in comments. They may genuinely care about the grammar quality of the code-base, but more than likely it was a script or auto-correcting plugin of the browser. I'm assuming the urge for simple spelling fixes is to forever mark the code change in the history of time with that author's mark.
Outside of the spelling fixes, there is a unique function in the Google that is responsible for looking for the word "Disallow" in the robots.txt files. Google commonly saw people worldwide misspell that, so they introduced this function.

This basically allows you to misspell the word in your robots.txt file and Google will still understand. It looks like common typos along with some regional spellings of the word.
While logic like this is pretty fast to run, I noticed a new pull-request to the project in the first 24 hours it was open sourced. They wanted to change this function to this:
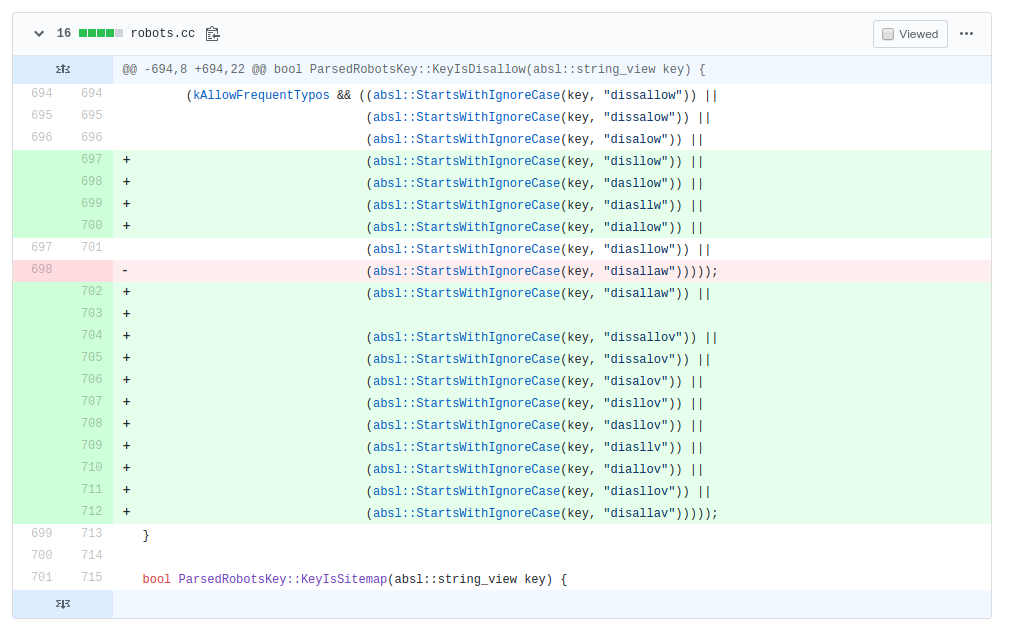
Which basically adds every iteration of the misspelling of the word. This much overkill for a parser that needs to be fast is just too much. Not to mention if you spell "disallow" wrong like "dissallov" do you deserve for Google to understand what you meant?
This is just one example of a recently open sourced project, but I enjoy reading them every time they come around.